젯슨 나노에서 yolo를 구동하면 성능이 썩 좋지는 않습니다.
저는 yolo4 기준으로 1fps 수준이 나와 실시간 추론을 하기엔 처리속도가 턱없이 부족했습니다.
이때 너무 높은 정확도가 필요하지 않다면 yolo configuration을 통해서 처리속도를 향상시킬 수 있습니다.
darknet 설치버전 yolo를 기준으로 합니다.
우선 darknet/cfg폴더에서 yolov4.cfg파일을 편집기로 엽니다.
해당 파일에서 yolo 추론 모델의 파라미터 세팅이 가능합니다.

batch : 1번에 처리되는 데이터 수
subdivisions : batch를 나눠서 처리하기 위한 값. 값이 커질수록 batch를 더 많이 나눠서 하므로 메모리가 작을수록 유리하나 속도는 떨어짐.
width : 입력 이미지 가로
height : 입력 이미지 세로
channels : 입력 이미지 차원
- 이때 입력 이미지 해상도는 추론 시 출력되는 이미지 해상도와는 다른 값이며 입력 이미지의 해상도가 커질수록 더 많은 픽셀로 나눠서 입력하므로 정확도는 향상되나 처리 속도는 떨어질 수 있음.
angle : data augmentation을 위 이미지 각도 변경 값
max_batches : 최대 batch 수 ( =class*2000. 각 클래스당 2000장의 학습 데이터가 권장됨을 의미)
steps : max_batches의 80%, 90% 값
기본 설정 후 정의된 각 convolution 레이어 정의 코드를 지나 첫번째 mask 정의 파트가 나옵니다.

mask : 해당 추론 파트에서 사용할 anchor 인덱스
anchors : 앵커 박스 가로, 세로 정의
- 첫번째 박스의 가로, 첫번째 박스의 세로, 두번째 박스의 가로, 두번째 박스의 세로, ... ,
classes : 클래스 수
num : 앵커 박스 정의 수
mask 직전의 마지막 convolutional 레이어의 필터값은 클래스값에 의해서 정해집니다.
filters = (classes+5)*num_of_anchors
yolo4에서 mask 추론 단계는 총 3번 나옵니다. 모두 수정해줍니다.
추가로, darknet yolo의 초기 출력 해상도는 1920x1280으로 굉장히 높게 설정돼있습니다.
해상도를 낮춰 추론 속도를 높여보도록 하겠습니다.
darknet 폴더 내 src 폴더에서 image_opencv.cpp 파일을 실행합니다.

해당 코드 내에 약 610번째 라인에 다음 코드를 수정합니다.
width, height에는 원하는 출력 해상도를 입력합니다.
cap->set(CV_CAP_PROP_FRAME_WIDTH, 1920);
cap->set(CV_CAP_PROP_FRAME_HEIGHT, 1280);
->
cap->set(cv::CAP_PROP_FRAME_WIDTH, width);
cap->set(cv::CAP_PROP_FRAME_HEIGHT, height);이때, 사용하는 카메라의 출력 해상도 사양 내에서 선택해야 합니다.
카메라 번호를 확인하고, 해당 포트의 사양을 확인하는 명령어 입니다.
$ ls /dev/video*
$ v4l2-ctl -d /dev/video[num] --list-formats-ext
src 폴더내의 파일을 수정한 후에는 make로 빌드를 해줘야 합니다.
$ /darknet$ make
yolo parameter 및 해상도 수정(640x480) 후 yolo4를 다시 구동해보았습니다. 초기 1fps 미만인 속도가 3fps까지는 올라왔습니다.

yolo4 tiny 버전으로 시도해보겠습니다.
동일하게 yolov4.cfg 파일 내의 인자들을 수정하고 해상도를 줄였습니다.
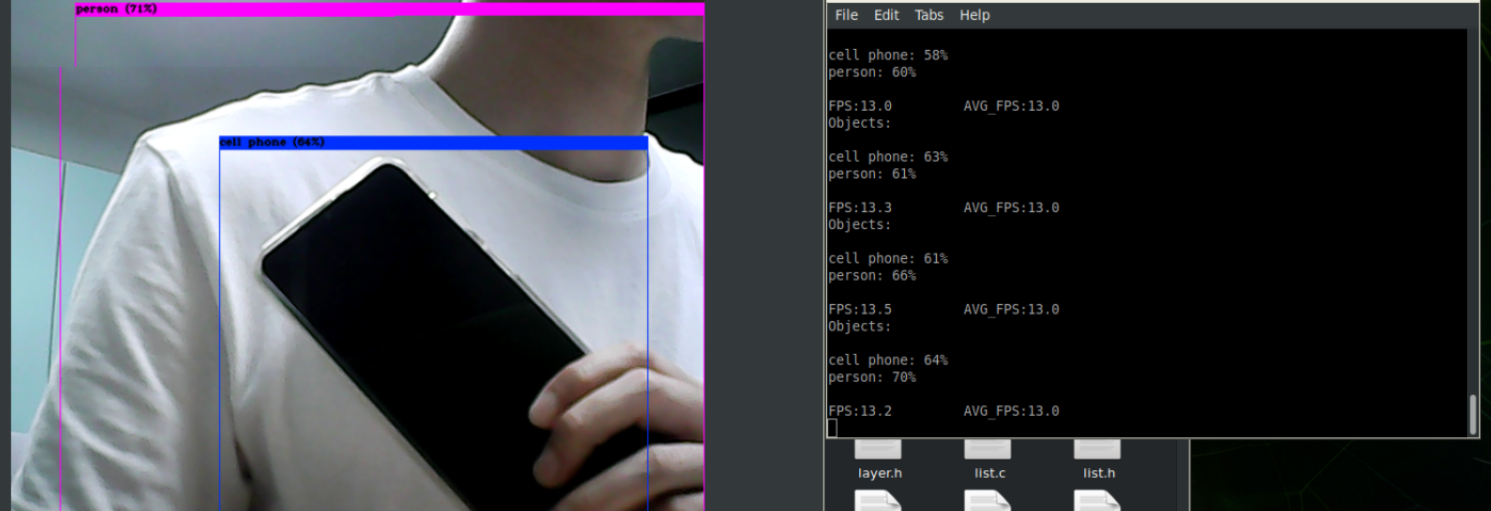
13fps내외로 기존 tiny 버전 세팅에 비해 fps가 2~3배 정도 향상됐습니다..
기본 버전에 비해 정확도는 약간 부족합니다만 얼굴까지 포함하면 웬만한 사람은 90% 이상으로 person으로 인식합니다.
도움이 됐으면 좋겠습니다.
감사합니다.
'AI > CNN' 카테고리의 다른 글
| 젯슨 나노 object detection을 위한 Yolo 구동 환경 구축 (0) | 2023.08.10 |
|---|